Besoin d’un accompagnement ?

- Marketing
- Web
Comprendre les codes de statut de réponse HTTP
Résumer l’article avec l’IA :
(Un compte peut être nécessaire selon l'agent IA.)
Chaque fois qu’un utilisateur visite un site web, un échange invisible s’effectue entre son navigateur et le serveur qui héberge le site. Pour communiquer entre eux, ces systèmes utilisent le protocole HTTP (HyperText Transfer Protocol), un langage standard du web permettant de transmettre des pages, des images, des fichiers ou encore des données.
Dans ce processus, le serveur renvoie systématiquement une réponse sous la forme d’un code HTTP. Ce code, composé de trois chiffres, indique le résultat de la requête effectuée par le navigateur. Par exemple, un code 200 signifie que la page a bien été chargée, tandis qu’un code 404 indique qu’une ressource demandée est introuvable. Ces réponses jouent un rôle essentiel dans le bon fonctionnement du web, même si elles restent souvent invisibles pour l’utilisateur final.
Les codes HTTP sont importants à plusieurs niveaux. Pour les utilisateurs, ils influencent directement l’expérience de navigation : une erreur serveur ou une page introuvable peut rapidement provoquer frustration et abandon. Pour les développeurs et administrateurs système, ils permettent d’identifier et de corriger des problèmes techniques. Enfin, pour le SEO, ces codes sont fondamentaux : Google s’appuie sur eux pour comprendre l’état des pages, gérer le crawl et décider de l’indexation des contenus.
Comprendre les différentes familles de codes HTTP
Les codes HTTP sont organisés en plusieurs grandes familles, chacune correspondant à un type de réponse précis envoyé par le serveur. Le premier chiffre du code permet d’identifier rapidement la nature de la réponse : information, succès, redirection ou erreur. Comprendre ces catégories est essentiel pour analyser le comportement d’un site web, corriger des problèmes techniques et optimiser ses performances SEO.
Les codes 1xx : les réponses d’information
Les codes 1xx correspondent à des réponses intermédiaires envoyées par le serveur avant la réponse finale. Ils servent principalement à gérer des échanges techniques entre le navigateur et le serveur, comme la poursuite d’une requête ou la confirmation qu’une connexion est en cours.
Ces codes restent généralement invisibles pour les utilisateurs et ont peu d’impact direct sur l’expérience web classique. Ils sont surtout utilisés dans des contextes techniques spécifiques ou des échanges complexes entre applications.
Les codes 2xx : les réponses de succès
Les codes 2xx indiquent que la requête a été traitée correctement par le serveur. Le plus connu est le célèbre 200 OK, qui signifie que la page ou la ressource demandée a été chargée avec succès.
Un autre code fréquent est le 201 Created, utilisé lorsqu’une nouvelle ressource a été créée, notamment dans les API ou certains formulaires dynamiques. Particulièrement importantes pour le SEO, ces réponses signalent à Google que les pages sont accessibles et peuvent être explorées et indexées correctement. Un site renvoyant majoritairement des codes 200 facilite le travail des moteurs de recherche et améliore la qualité globale du crawl.
Les codes 3xx : les redirections
Les codes 3xx indiquent qu’une ressource a été déplacée ou qu’une action supplémentaire est nécessaire pour accéder au contenu demandé. Les plus connus sont les 301 et 302.
Une redirection 301 correspond à un déplacement permanent d’une page. Elle est largement utilisée lors de refontes de sites, de changements d’URL ou de migrations SEO afin de transmettre la popularité et le référencement de l’ancienne page vers la nouvelle.
La redirection 302, quant à elle, indique un déplacement temporaire. Elle doit être utilisée lorsque la redirection n’a pas vocation à durer dans le temps.
Ces redirections ont un impact direct sur le SEO et l’expérience utilisateur. Une mauvaise gestion des redirections peut provoquer des pertes de trafic, des erreurs de crawl ou des ralentissements dans la navigation.
Les codes 4xx : les erreurs côté client
Les codes 4xx correspondent à des erreurs liées à la requête envoyée par l’utilisateur ou le navigateur. Le plus connu est le 404 Not Found, qui indique qu’une page est introuvable. Cela peut être causé par une URL incorrecte, une page supprimée ou un lien cassé.
Le code 403 Forbidden signifie que l’accès à la ressource est interdit, même si celle-ci existe. À l’inverse, le 401 Unauthorized indique qu’une authentification est nécessaire pour accéder au contenu.
Ces erreurs peuvent nuire à l’expérience utilisateur et au référencement naturel si elles sont trop nombreuses ou mal gérées. Les erreurs 404, notamment, doivent être surveillées régulièrement afin d’éviter les liens morts et les pertes de visibilité SEO.
Les codes 5xx : les erreurs côté serveur
Les codes 5xx signalent des problèmes directement liés au serveur. Contrairement aux erreurs 4xx, l’utilisateur n’est pas responsable ici : le problème vient de l’infrastructure ou de l’application web elle-même.
Le code 500 Internal Server Error est l’une des erreurs les plus fréquentes et indique un dysfonctionnement interne du serveur. Le 502 Bad Gateway apparaît généralement lorsqu’un serveur intermédiaire reçoit une réponse invalide d’un autre serveur. Enfin, le 503 Service Unavailable signifie que le serveur est temporairement indisponible, souvent en raison d’une maintenance ou d’une surcharge.

Les codes erreurs HTTP les plus courants et leurs impacts
Parmi l’ensemble des réponses HTTP existantes, certains codes reviennent particulièrement souvent dans la gestion quotidienne d’un site web. Qu’il s’agisse de pages supprimées, de redirections mal configurées ou de problèmes serveur, ces erreurs peuvent avoir des conséquences importantes sur l’expérience utilisateur, les performances techniques et le référencement naturel.
404 : page introuvable
L’erreur 404 Not Found est sans doute la plus connue. Elle apparaît lorsqu’une page demandée n’existe plus ou ne peut pas être trouvée par le serveur. Plusieurs causes peuvent expliquer ce problème : suppression d’un contenu sans redirection, modification d’URL, faute de frappe dans un lien ou encore erreur dans le maillage interne.

D’un point de vue UX, une erreur 404 peut rapidement frustrer les visiteurs, surtout si elle survient au cours d’un parcours important. Côté SEO, les pages introuvables peuvent perturber le crawl de Google et provoquer une perte de popularité si des backlinks pointaient vers ces URLs supprimées.
Pour bien gérer une page 404, il est recommandé de proposer une page d’erreur personnalisée, claire et utile, permettant à l’utilisateur de poursuivre sa navigation. Il est également important de mettre en place des redirections 301 lorsque des contenus sont déplacés ou supprimés définitivement.
301 & 302 : les redirections
Les redirections sont essentielles pour guider correctement les utilisateurs et les moteurs de recherche lorsqu’une URL change. La 301 doit être utilisée pour un déplacement permanent, par exemple lors d’une refonte de site ou d’une migration SEO. Elle permet de transmettre l’autorité SEO de l’ancienne page vers la nouvelle.
La 302, à l’inverse, correspond à une redirection temporaire. Elle est utile lorsqu’un contenu est déplacé provisoirement, sans intention de modification définitive. Les erreurs de redirection sont fréquentes : chaînes de redirections multiples, boucles infinies ou mauvais choix entre 301 et 302. Ces problèmes peuvent ralentir le chargement des pages, perturber l’indexation et dégrader l’expérience utilisateur.
500 & 503 : les erreurs serveur
Les erreurs 500 Internal Server Error et 503 Service Unavailable signalent des problèmes côté serveur. Elles sont souvent liées à des erreurs de configuration, des conflits techniques, une surcharge de trafic ou des limitations d’hébergement.
Une erreur 500 indique généralement un dysfonctionnement interne empêchant le serveur de répondre correctement. Le code 503, quant à lui, est souvent utilisé lors d’opérations de maintenance ou lorsque le serveur est temporairement indisponible. Si Google rencontre régulièrement des erreurs serveur lors du crawl, cela peut ralentir l’exploration du site, empêcher certaines pages d’être indexées et envoyer des signaux négatifs sur la fiabilité globale du site.
401 & 403 : les accès restreints
Les codes 401 Unauthorized et 403 Forbidden concernent les restrictions d’accès. Le premier indique qu’une authentification est nécessaire pour accéder à une ressource, tandis que le second signifie que l’accès est explicitement interdit, même si l’utilisateur est identifié.
Ces réponses sont fréquentes sur les extranets, back-offices, espaces membres ou interfaces d’administration. Elles permettent de protéger certaines ressources sensibles et de limiter leur accès à des utilisateurs autorisés uniquement. Toutefois, une mauvaise configuration de ces permissions peut parfois bloquer des contenus importants pour les moteurs de recherche ou empêcher certains utilisateurs légitimes d’accéder aux pages concernées.
Votre site Web a besoin d’un audit ?
Comment analyser et corriger les erreurs HTTP ?
Google s’appuie en effet sur les codes HTTP pour comprendre l’état des pages, identifier les contenus accessibles et gérer l’exploration du site. Des erreurs mal gérées peuvent ralentir le crawl, empêcher l’indexation de certaines pages ou dégrader la qualité perçue du site par les moteurs de recherche. C’est pourquoi l’analyse et la correction des erreurs HTTP constituent une étape essentielle de tout audit technique SEO.
Google Search Console
On en parle régulièrement, la Google Search Console est l’un des premiers outils à consulter pour identifier des problèmes HTTP. La plateforme permet de détecter les pages introuvables (404), les erreurs serveur (5xx) ou encore les URLs bloquées par des problèmes d’accès.
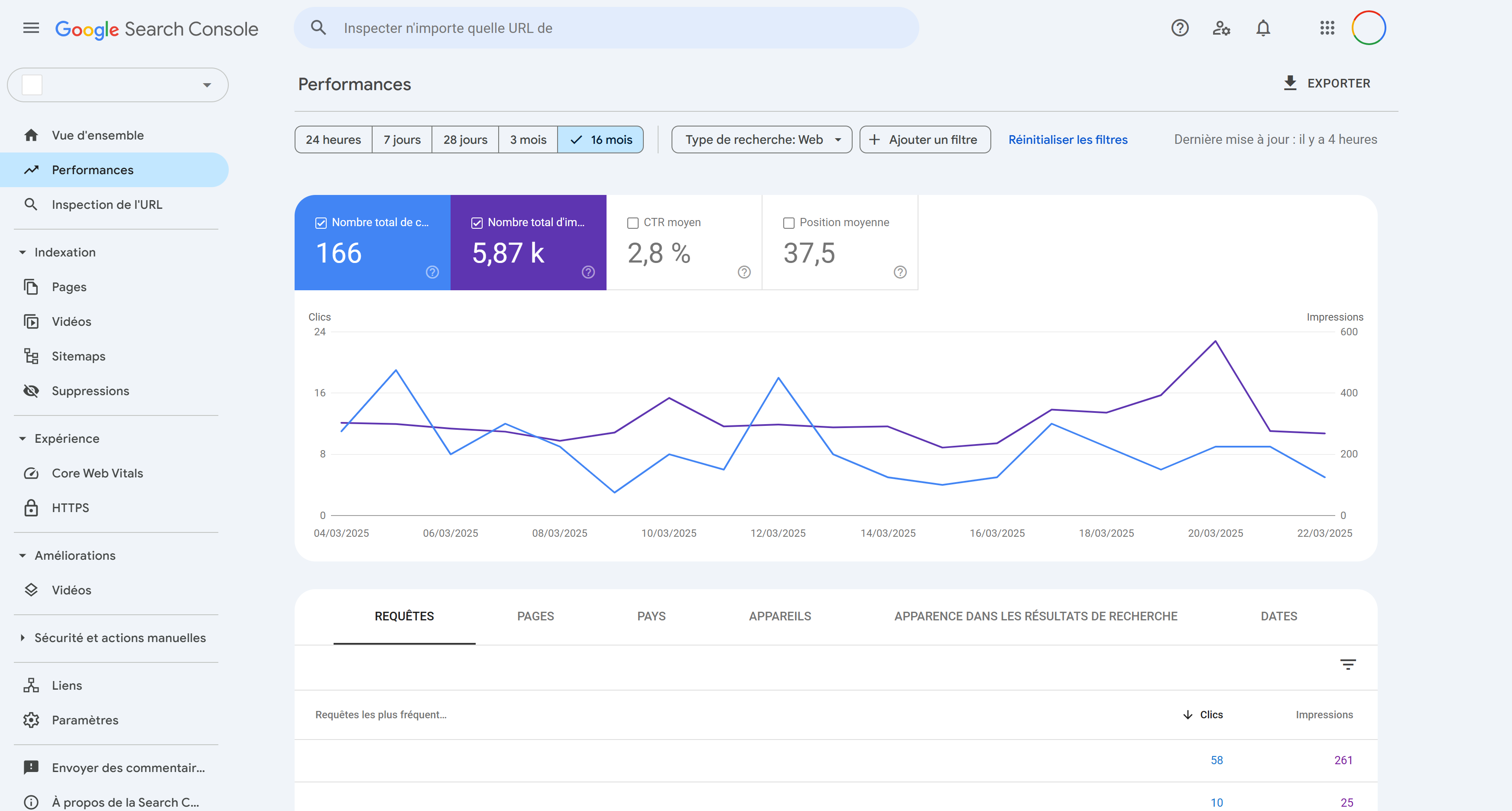
Elle offre également une vision précise de la manière dont Google explore le site et signale les erreurs pouvant affecter l’indexation. Pour les référenceurs, c’est un outil indispensable afin de prioriser les corrections techniques et surveiller la santé globale du site.
Screaming Frog et les outils de crawl
Des outils comme Screaming Frog, Sitebulb ou Siteliner permettent d’analyser un site comme le ferait un moteur de recherche. Ils détectent automatiquement les codes HTTP renvoyés par chaque page : erreurs 404, redirections, erreurs serveur ou contenus dupliqués.
Ces outils sont particulièrement utiles pour repérer :
- des liens cassés,
- des chaînes de redirections,
- des pages orphelines,
- ou encore des erreurs techniques invisibles à première vue.
Logs serveur et monitoring
L’analyse des logs serveur permet d’aller encore plus loin. Les logs enregistrent toutes les requêtes effectuées sur le site, qu’elles proviennent d’utilisateurs ou des robots des moteurs de recherche.
Cette approche permet notamment d’identifier :
- les erreurs rencontrées par Googlebot,
- les pages les plus crawlées,
- les problèmes récurrents de serveur,
- ou encore les URLs générant des erreurs fréquentes.
Les bonnes pratiques techniques
Pour limiter les erreurs HTTP, plusieurs bonnes pratiques doivent être mises en place :
- vérifier régulièrement les liens internes et externes,
- éviter les chaînes de redirections inutiles,
- mettre en place des redirections 301 propres lors des changements d’URL,
- personnaliser les pages 404,
- surveiller les performances serveur et les temps de réponse.
Une surveillance continue indispensable
Les erreurs HTTP ne sont pas des problèmes ponctuels à corriger une seule fois. Elles évoluent avec les mises à jour du site, les migrations, les suppressions de contenus ou les changements techniques.
Mettre en place une surveillance continue permet d’anticiper les problèmes avant qu’ils n’impactent le SEO ou les utilisateurs. Dans un environnement où les performances techniques jouent un rôle croissant dans le référencement, le monitoring web devient un levier essentiel pour maintenir un site performant, accessible et correctement indexé.
Souvent invisibles pour les utilisateurs, les codes HTTP jouent pourtant un rôle fondamental dans le fonctionnement du web. Ils constituent le véritable langage d’échange entre les navigateurs et les serveurs, permettant de transmettre des informations essentielles sur l’état des pages, des ressources et des requêtes. Au-delà de leur dimension technique, ces réponses ont un impact direct sur l’expérience utilisateur, la stabilité d’un site et son référencement naturel. Une erreur mal gérée peut dégrader la navigation, ralentir le crawl des moteurs de recherche ou affecter la visibilité SEO d’un site.
C’est pourquoi une bonne gestion des codes HTTP est indispensable pour garantir la performance globale d’un projet web. Surveillance, optimisation et correction des erreurs doivent faire partie intégrante de toute stratégie technique et SEO durable.
- Comprendre les différentes familles de codes HTTP
- Les codes erreurs HTTP les plus courants et leurs impacts
- Comment analyser et corriger les erreurs HTTP ?

